lantern パッケージの紹介
はじめに
この記事は R Advent Calendar 2020 22日目の記事です。
今年は色々ありまして、まさかの1年ぶりの記事更新です。
lantern パッケージは、平たく言えば tidymodels で torch のモデリングを提供するものです。 この一文で意味が分かる方は少し飛ばして次節の「インストール」以降をお読みください。 github.com
10月末頃に、Pythonに依存しないディープラーニングライブラリとして torch パッケージがリリースされました。 Rでディープラーニングの学習や生成モデルをつくるパッケージは RStudio から keras や tensorflowなどが提供されていましたが、これらはPythonの同名ライブラリのメソッドを reticulate パッケージを通して呼び出すという仕様のため、環境構築の際に一手間かかっていました。
一方、tidymodels はtidyverseの流儀に倣って、「統一したフレームワークで」「直感的に」モデリングする環境を提供するパッケージです。もともとRは統計解析のために開発された言語ということがあって、様々な統計モデリングの手法が様々なパッケージで提供されてきましたが、「引数の順番や入力データの形式がパッケージによって異なるため、様々な分析を同時に実行するのが面倒」という欠点がありました。tidymodels パッケージはこのような欠点を補う一助になります。
tidymodelsの基本的な使い方は、dropout009さんの記事などが参考になります。
ただし、現状tidymodelsでは有名なモデリング手法しかオフィシャルには提供されておらず、必ずしも自分がやりたいモデルがあるとは限りません。 足りないモデルがあれば、他のパッケージによるtidymodels用のインターフェース提供を期待するか、自分で用意しなければなりません。このあたりは、atusyさんによる14日目の記事が詳しいです。
lantern パッケージは、この「tidymodels用のインターフェース提供」をしてくれるパッケージです。ただし、開発がtidymodelsになっているので、将来的にオフィシャルに組み込まれる可能性はあるかもしれません。。。
また、本記事執筆時点(2020-12-21)で lantern パッケージのライフサイクルは「experimental」つまりまだ実験的な立ち位置のパッケージになりますので、以下で書くことは今後変わる可能性がありますので、ご注意ください。
以下、tidymodelsの基本的な使い方(レシピの組み方など)と、ディープラーニングの基本的なこと(エポックとか隠れ層とか)がある程度分かっている前提のお話になります。
インストール
CRANにはまだ来ていないので、 GitHubからインストールします
remotes::install_github("tidymodels/lantern")
このとき、torch パッケージがインストールされていない場合は一緒にインストールされます。
また、以下で使うデータのために、 modeldata というパッケージもインストールしておきます。
install.packages("modeldata")
あと、もし tidymodels のインストールがまだの人がいたらここでインストールしておきます
install.packages("tidymodels")
試してみる
GitHubに出ている例をなぞってみます。
データセットの準備
# 2値分類のためのデータセットがロードされる data(bivariate, package = "modeldata")
前処理レシピの作成
ここでは、元データに対して Yeo-Johnson変換 1と正規化を行っています。
recopes::all_predictors は、tidyverseで言うところの dplyr::everything()のようなもので、「すべての特徴量に対して」同じ前処理を行うことを意味しています。
rec <- recipes::recipe(Class ~ ., data = bivariate_train) %>% recipes::step_YeoJohnson(recipes::all_predictors()) %>% recipes::step_normalize(recipes::all_predictors())
学習する
普通のtidymodelsの運用ではここで recipes::prep(前処理の適用) → parsnip::手法の関数 (rand_forestなど) → parsnip::set_engine() → parsnip::fit() (学習) → predict() (予測)、という順番で学習・評価をを行っていくのですが、 lantern パッケージは torch のディープラーニング専用の関数を提供するパッケージなので、predict() 直前までは一つの関数内でやれちゃいます。つまり学習関数に前処理レシピを直接入れる形になります。
nn_rec_biv <- lantern::lantern_mlp(rec, data = bivariate_train, epochs = 150, hidden_units = 3, batch_size = 64)
エポック数や隠れ層ディープラーニングの設定項目は、 lantern::lantern_mlp 内の引数で設定できます。
他に設定できる項目は
activation: 活性化関数の種類 。"relu", "elu", "tanh", and "linear"から選択。デフォルトは "relu"のランプ関数penalty: 正則化のペナルティの量。デフォルトは0dropout: Dropout率2。デフォルトは0lean_rate: 学習率。デフォルトは0.01momentum: 勾配降下のモーメントパラメータ。デフォルトは0.0
です。また、verbose = TRUE を設定すると学習の様子がコンソールに出力されます。
予測する
今回のタスクは2値分類だったので、それぞれのクラスに所属される確率で予測をします。
# 予測して正解をくっつける pred_nn_biv <- predict(nn_rec_biv, bivariate_test, type = "prob") %>% dplyr::bind_cols(bivariate_test) # AUC pred_nn_biv %>% yardstick::roc_auc(Class, .pred_One) #> # A tibble: 1 x 3 #> .metric .estimator .estimate #> <chr> <chr> <dbl> #> 1 roc_auc binary 0.859
以下は lantern ではなく tidymodels の知識になりますが、Accuracy, Precision, Recallの算出とROCカーブの描画は以下のような感じです。
# 評価のメトリックをセット multi_met <- yardstick::metric_set(yardstick::accuracy, yardstick::precision, yardstick::recall) # Accuracy, Precision, Recall pred_nn_biv %>% dplyr::mutate(pred_Class = dplyr::if_else(.pred_One > 0.5, "One", "Two")) %>% dplyr::mutate(pred_Class = as.factor(pred_Class)) %>% multi_met(truth = Class, estimate = pred_Class) #> # A tibble: 3 x 3 #> .metric .estimator .estimate #> <chr> <chr> <dbl> #> 1 accuracy binary 0.782 #> 2 precision binary 0.839 #> 3 recall binary 0.823 # ROCカーブ pred_nn_biv %>% yardstick::roc_curve(Class, .pred_One) %>% lantern::autoplot() # ggplot2::autoplotがそのままexportされている
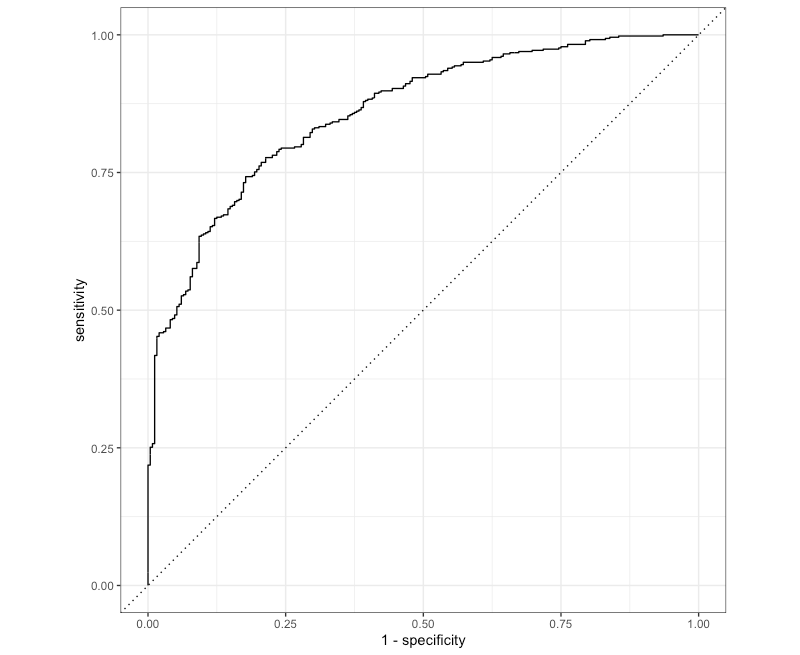
正直、機械学習モデルとしてはもっと頑張れよという感じですが、 lantern を動かすことが目的なのでハイパーパラメータのチューニングは本記事ではやりません。
まとめ
本記事では、lantern パッケージを使って tidymodels の中で torch で組まれたディープラーニングモデルを動かす手法について紹介しました。
R Advent Calendar、明日はhkzmさんの「ALTREPについて」です。